A little over a year ago, I experimented with seeing is the current AI models could do logic puzzles. I used to do these kind of puzzles often when I was a kid, in the pre-interweb era.
At the time I tested them, they all failed to solve the puzzles correctly.
Fast forward to today, and the release of Anthropic’s Claude Fable model.
I gave Fable the same logic puzzle that the earlier Claude model failed.

Here is my initial prompt. Took less than a minute for Fable to respond.
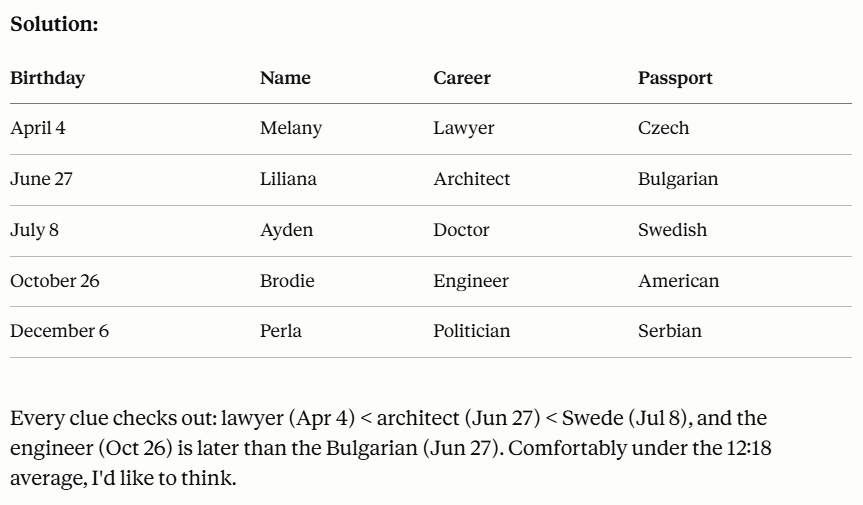
The answer was correct and even presented in a nice table. It even brags a little about it’s speed.
This kind of reasoning is difficult and this is a marked improvement from the last test.
LLMs still have a lot of issues with guessing, going down rabbit holes, and not sticking to Occam’s Razor, but improvements in this kind of reasoning is impressive.