
After playing with AI and basic cryptography, I decided to see if the various AI systems could solve basic logic puzzles. These puzzles were a childhood favorite. Is it any surprise that I ended up as an engineer?
I stopped by a local bookstore and picked up a book of logic puzzles.
Below is what logic puzzles look like. A few sentences and a grid to help solve the puzzle.

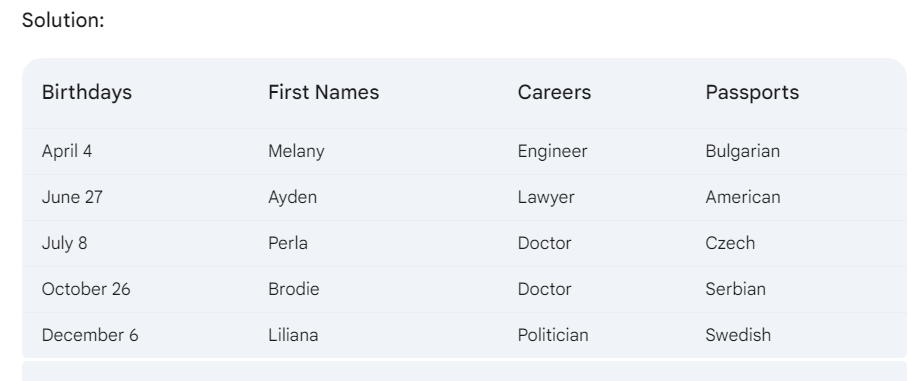
As the human control subject, I did the puzzle and checked the answer.
Solving these puzzles involves thinking about what you can infer from the information and tracking it on the grid. It’s kind of like Boolean logic to some degree being able to rule out possible answers and marking with a X. After doing a few puzzles, you learn the grid is incredibly helpful in ruling out possibilities and arriving at logical facts.
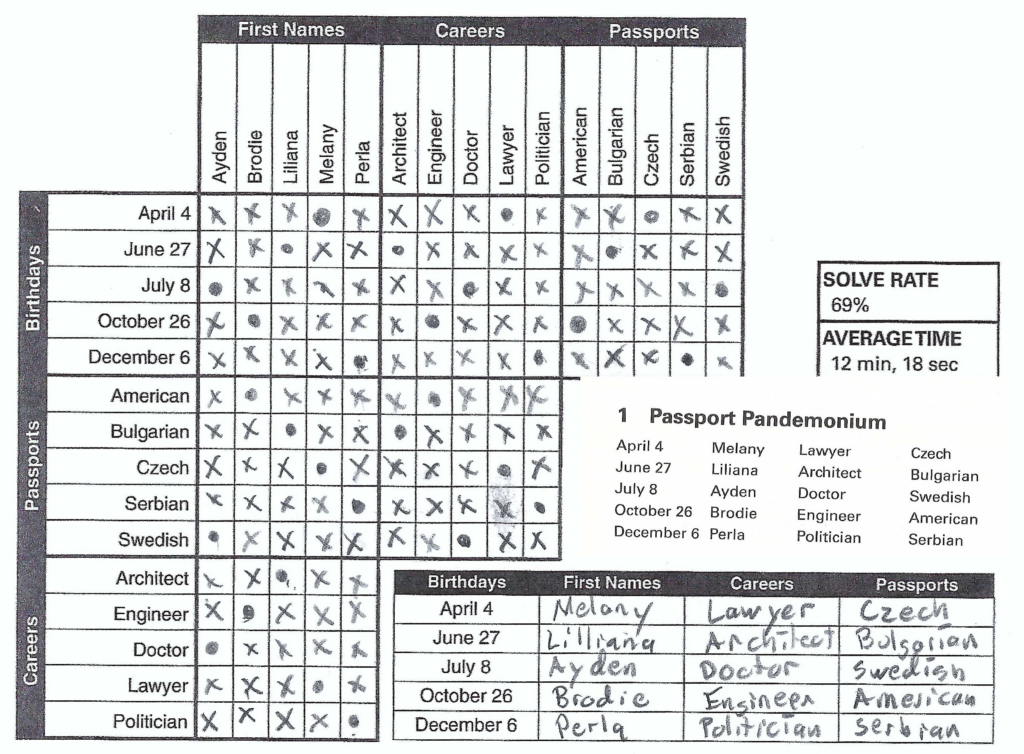
My prompt to each model was “Complete this logic puzzle and provide the birthday, first name, career, and passport of each person mentioned”
Claude, ChatGPT, Gemini, Meta AI, Mistral, and Deepseek-R1 all got it wrong. Deepseek-r1:8B hallucinated. Here are Claude & ChatGPT’s answers


I then told each “That is incorrect. Please try again.” Each failed a second time to get it correct.
Some got close with a few things off, but none of them got it correct. Most seemed to understand what they were trying to solve, but there were some oddities.
This is Gemini 2.0 Flash’s answer. Note it has Doctor entered twice, showing it doesn’t understand a key element of the puzzle.
Deepseek-r1:8B running locally on Ollama completely hallucinated and started inventing random names, passport numbers, and occupations.

In each case, the models presented their solution as correct and valid. But they are actually incorrect. Even after telling them that they were incorrect, they were unable to arrive at the correct answers.
This gets to the main learning of this exercise; LLMs are not always right, even if they have confidence in their answers. Without a method to check the validity of a model’s work and conclusion, the risk of faulty answers is real.
In my simple test, I am able to validate the correct answers and compare with the results from the models. But in more complicated cases this might not be possible.
Imagine using an LLM to calculate the loads in a building design. Should you believe the answer? It’s one thing to get a silly puzzle wrong, nothing bad happens. But if a wrong answer ends up in a building collapse, there are huge real world risks.
LLMs will continue to improve, but without reliable methods to verify their outputs, the risk of incorrect conclusions remains, especially in high-stakes applications like engineering or medicine.